

e公司
02-14 16:40
DeepSeek大消息,梁文锋参与署名
来源:e公司
2026-01-01 20:36
Aa
大号字
1月1日消息,DeepSeek发布了一篇新论文,提出了一种名为mHC(流形约束超连接)的新架构。该研究旨在解决传统超连接在大规模模型训练中的不稳定性问题,同时保持其显著的性能增益。这篇论文的第一作者有三位:Zhenda Xie(解振达)、Yixuan Wei(韦毅轩)、Huanqi Cao。值得注意的是,DeepSeek创始人梁文锋也在作者名单中。

论文摘要指出,近来,以超连接(HC)为代表的研究通过拓宽残差流宽度和多样化连接模式,拓展了过去十年间确立的普遍采用的残差连接范式。虽然这些改进带来了显著的性能提升,但连接模式的多样化从根本上削弱了残差连接固有的恒等映射特性,导致严重的训练不稳定性与受限的可扩展性,同时还造成了显著的内存访问开销。为了解决这些问题,DeepSeek提出了流形约束超连接(mHC)——一种通用框架,能够将HC的残差连接空间投影到特定流形上,从而恢复恒等映射特性,并融合严格的基础设施优化以确保运行效率。实证实验表明,mHC能够有效支持大规模训练,在提供明显性能提升的同时具备更优的可扩展性。DeepSeek预计,mHC作为HC的一种灵活而实用的拓展,将有助于深化对拓扑架构设计的理解,并为基座模型的演进指明富有前景的方向。
内部大规模训练结果显示,mHC可有效支持规模化训练,当扩展率????=4时,仅带来6.7%的额外时间开销。
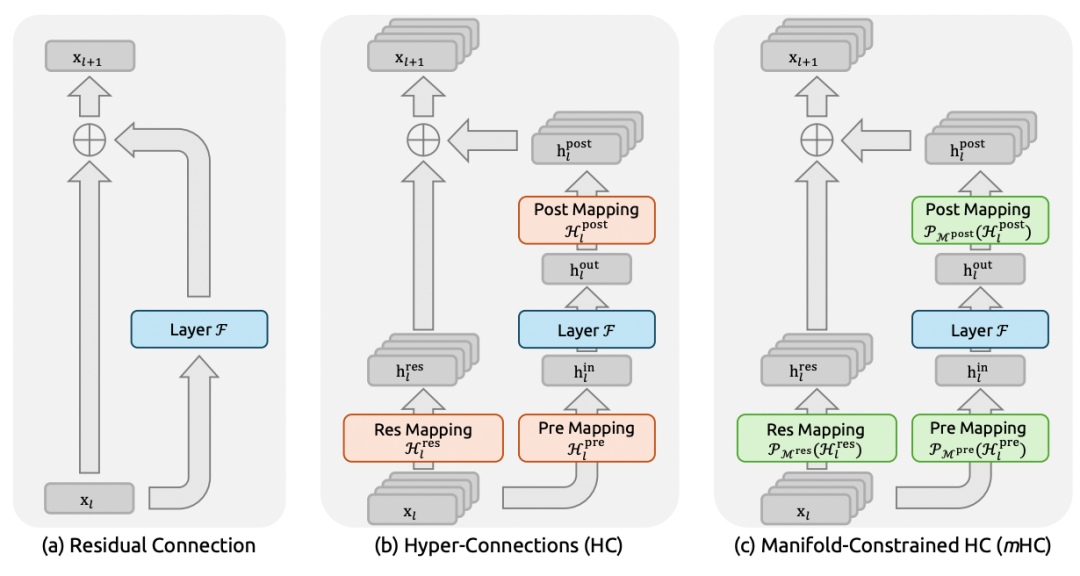
图为残差连接范式的示意图。本图对比了 (a) 标准残差连接、(b) 超连接 以及 (c) 流形约束超连接的结构设计。与无约束的HC不同,mHC通过将连接矩阵投影到一个约束流形上,专注于优化残差连接空间,从而确保训练的稳定性。
论文在结论与展望部分指出,实证结果表明,mHC能有效恢复恒等映射特性,相较于传统HC,能以更优的可扩展性实现稳定的大规模训练。关键的是,通过高效的基础设施级优化,mHC以可忽略的计算开销实现了上述改进。
论文还指出,作为HC范式的广义拓展,mHC为未来研究开辟了多个重要方向:虽然本研究采用双随机矩阵确保稳定性,但该框架可兼容针对特定学习目标设计的多种流形约束探索;预计对差异化几何约束的深入研究可能催生能更好权衡可塑性—稳定性关系的新方法。此外,DeepSeek希望mHC能重新激发学界对宏观架构设计的关注。通过深化对拓扑结构如何影响优化与表征学习的理解,mHC将有助于突破现有局限,并可能为下一代基础架构的演进指明新路径。
近期,DeepSeek动作不断。2025年12月1日,DeepSeek同时发布两个正式版模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale。
DeepSeek表示,DeepSeek-V3.2的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用Agent任务场景。在公开的推理类Benchmark测试中,DeepSeek-V3.2达到了GPT-5的水平,仅略低于Gemini-3.0-Pro;相比Kimi-K2-Thinking,V3.2的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale是DeepSeek-V3.2的长思考增强版,同时结合了DeepSeek-Math-V2的定理证明能力。该模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美Gemini-3.0-Pro。
2025年9月29日,DeepSeek宣布,正式发布DeepSeek-V3.2-Exp模型。作为迈向新一代架构的中间步骤,V3.2-Exp在V3.1-Terminus的基础上引入了DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。同时API大幅度降价。在新的价格政策下,开发者调用DeepSeek API的成本将降低50%以上。
2025年9月17日,在最新一期的国际权威期刊Nature(自然)中,DeepSeek-R1推理模型研究论文登上了封面。该论文由DeepSeek团队共同完成,梁文锋担任通讯作者,首次公开了仅靠强化学习就能激发大模型推理能力的重要研究成果。这是中国大模型研究首次登上Nature封面,也是全球首个经过完整同行评审并发表于权威期刊的主流大语言模型研究,标志着中国AI技术在国际科学界获得最高认可。
Nature在其社论中评价道:“几乎所有主流的大模型都还没有经过独立同行评审,这一空白终于被DeepSeek打破。”
来源:证券时报,综合自DeepSeek论文、证券时报此前报道
责任编辑: 戎艾茵
e公司声明:文章提及个股及内容仅供参考,不构成投资建议。投资者据此操作,风险自担。
更多相关文章
-

-
e公司 臧晓松 02-14 16:40

-
e公司 02-14 16:39

-
e公司 02-14 16:39

-
e公司 02-14 14:19

-
证券时报·e公司 康殷 02-14 13:48




